吴恩达在Coursera上又推出了一个新课程《Generative AI with Large Language Models》,学完以后发现非常不错,有系统性,又有实操性,所以把内容摘要在这里。
先来个大框架图,看一下搭建一个基于大模型的应用,怎么一步一步来做:
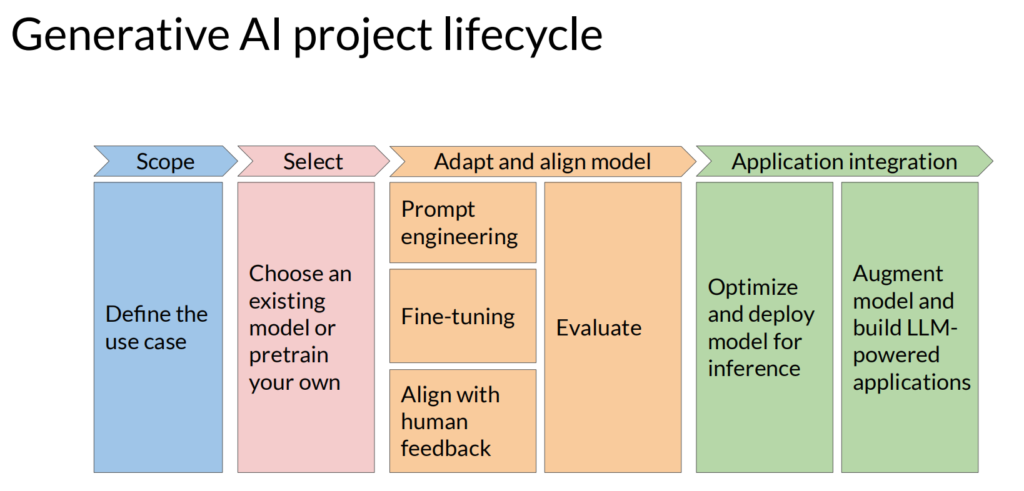
主要分为下面四个大步骤:确定场景、选择合适的预训练模型、基于应用场景对模型调优、最后模型部署和应用集成
1,确定场景:
目前AI应用场景主要包括:内容生成(文本、图片、音视频)、翻译、文本摘要和提取等等
2,选择合适的模型:
LLM大体上分成三类:
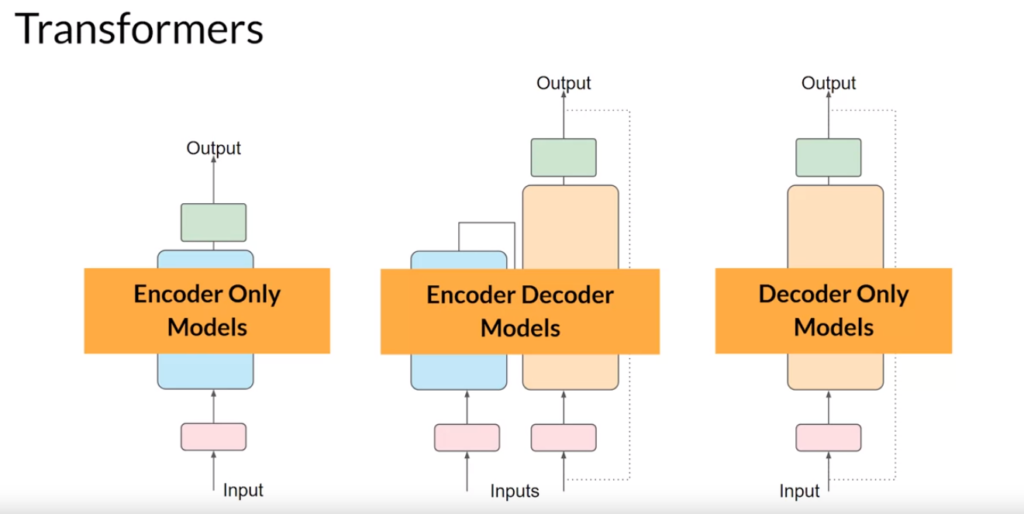
Encoder Only Models 又叫 Autoencodind Models,能利用上下文来生成缺失的内容,适合用于文本的情感分类、实体提取和单词分类。这类模型的代表就是BERT
Encoder Only Models 又叫 Autoregressive Models,它仅根据上文来生成后续内容,适合用于内容生成,这类模型的代表就是OpenAI的GPT、谷歌的BARD和Meta的LLaMA
Encoder Decoder Models 又叫 Sequence-to-Sequence Modles,它不直接对应上下文的词语,而是使用向量来预测内容,适合语言翻译、内容提取和问答,这类模型的代表包括T5和BART
关于transformers的更详细介绍,这里就不详细展开了。可以直接参考:Attention Is All You Need
根据要完成的任务,选择适合的大模型,还要注意模型的参数和精度,参数越多、精度越高,模型一般能力越强,但是成本成本也高,这里就需要平衡。
3,模型调优:
接下来是怎么把通用模型做优化,使得在特定场景下能够有更好的表现
3.1 Prompt engineering:
第一类方法不改变模型,也不需要训练,仅仅通过prompt里给模型一些提示,来改进模型的输出,所以也叫也叫In-context learning,根据是否在prompt中给输入输出举例,和举例的数量,分为下面几种:
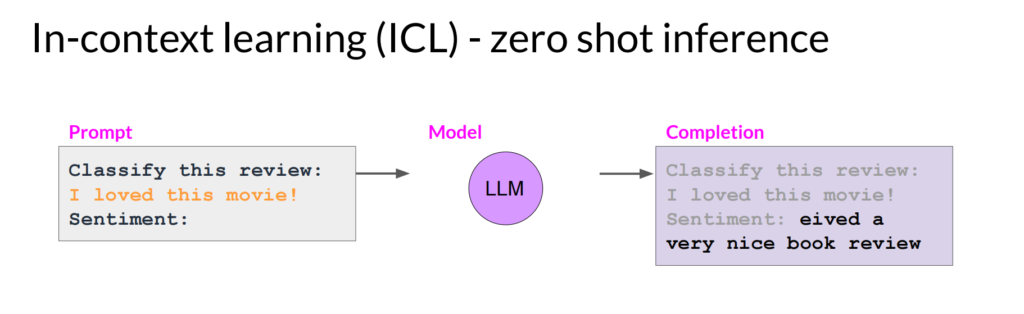
zero shot:通过prompt本身的一些结构,让模型输出更好的结果,比如:
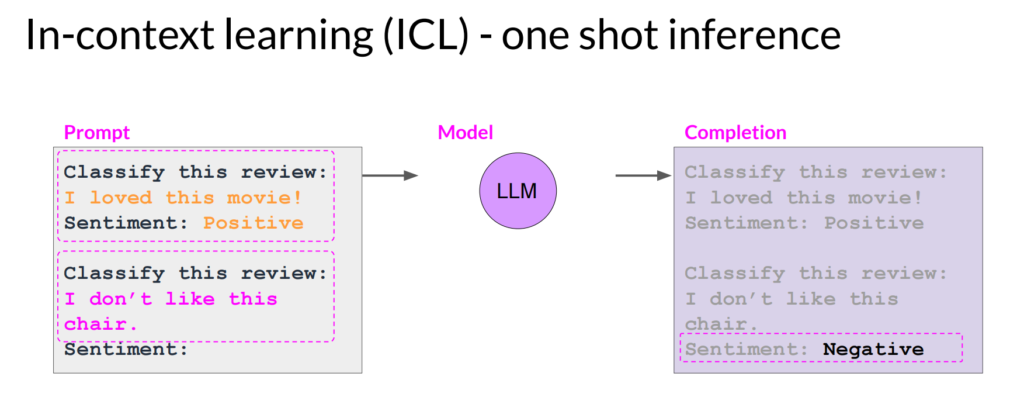
one shot:通过在prompt中给个例子,来让模型输出更好的结果,比如:
few shot:类似的,在prompt中给出多个例子(比如5-6个),来让模型输出更好的结果:
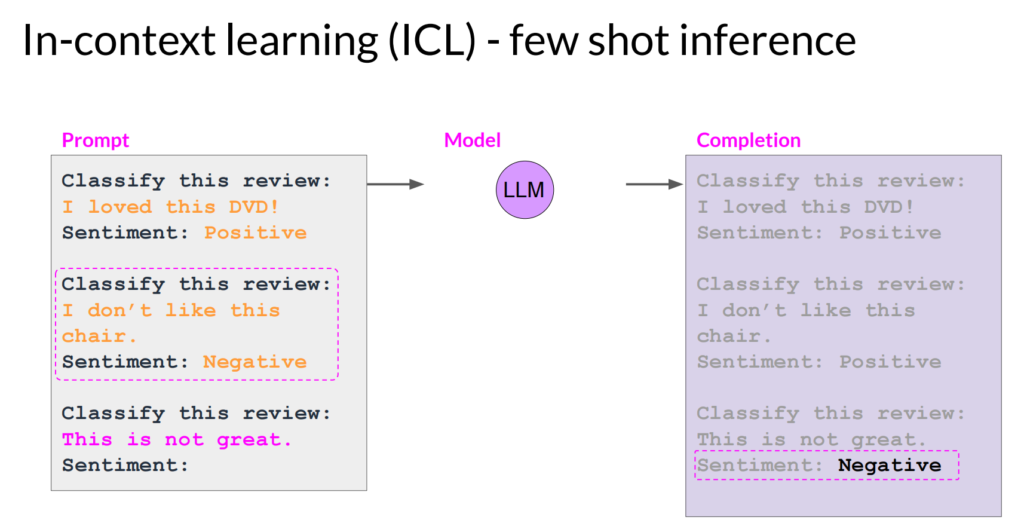
注意:当模型较小时,prompt工程的效果不会特别好
3.2 Prompt tuning and fine-tuning
第二类方法,用专门的数据对预训练好的通用大模型进行调优,一般针对某个任务,专门提供一些样本,来对模型进行训练,针对单个任务进行训练,就是通过标注好的数据集对模型进行进一步调优
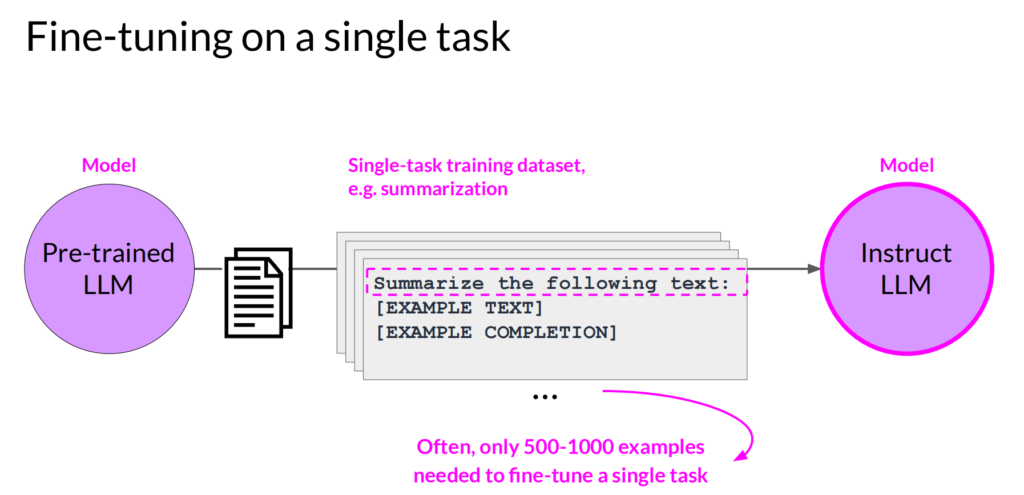
但是这样做会遇到一个问题,就是Catastrophic forgetting,也就是模型会忘记以前的训练结果,针对其他任务,输出结果会变差,有两种方法来避免:
一种是使用多任务进行调优,叫Multi-task instruction fine-tuning
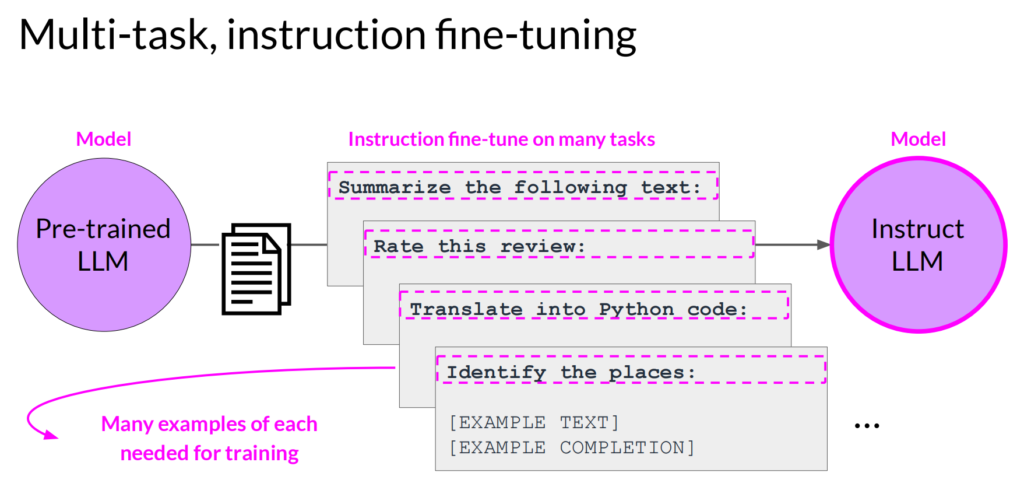
就是用多种任务的数据,对模型进行训练,增强模型在不同情况下的表现。
另一种方法就是Parameter efficient fine-tuning (PEFT),通过冻结大部分参数,只训练小部分参数来进行:
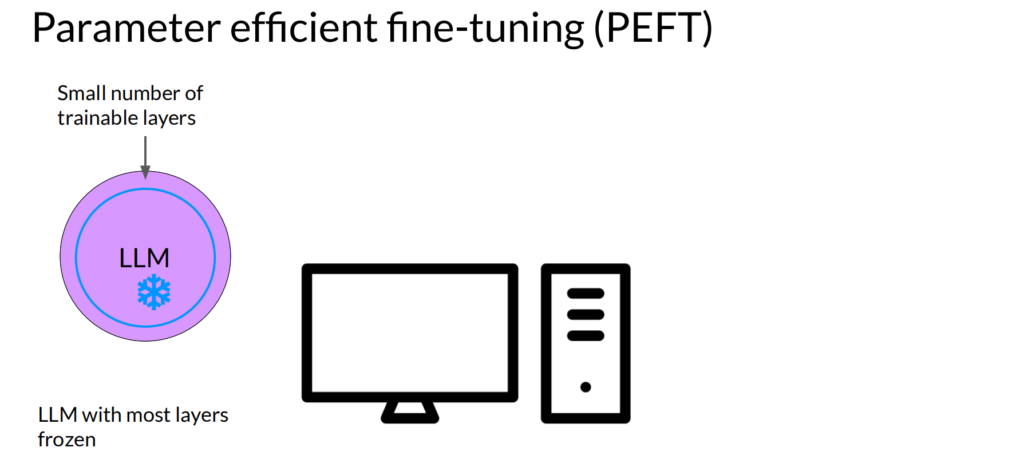
或者冻结整个模型的参数,然后在原有模型外增加额外参数来训练:
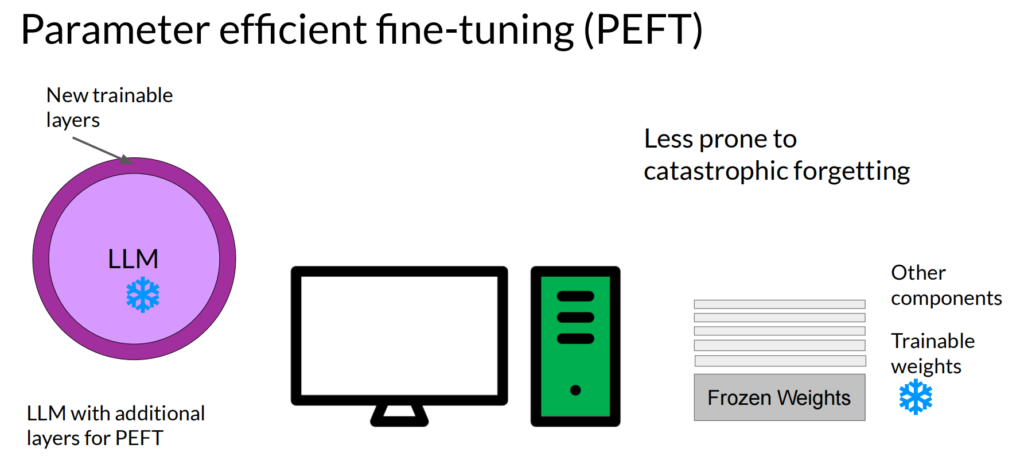
来对模型进行调优。
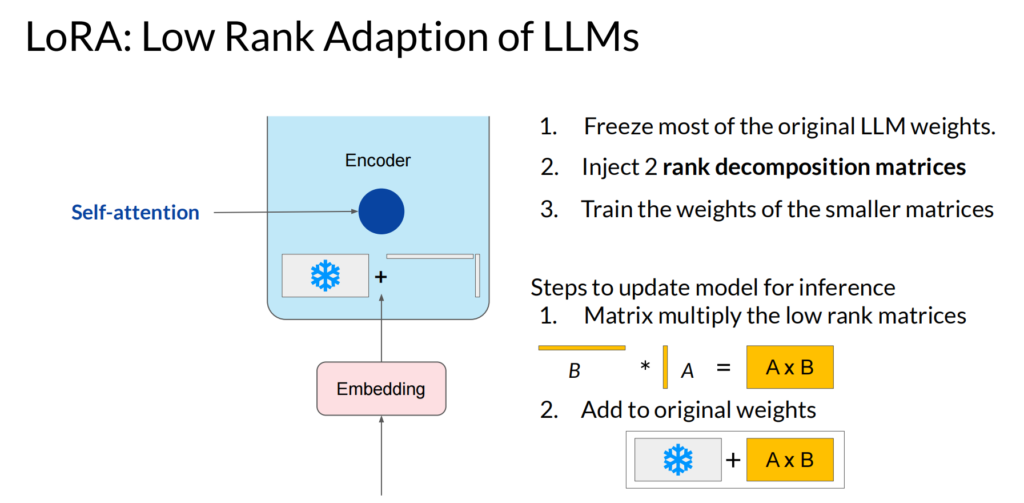
这里常见的算法就是Low-Rank Adaptation of Large Language Models (LoRA),原理如下:
几种方法的效果对比如下:
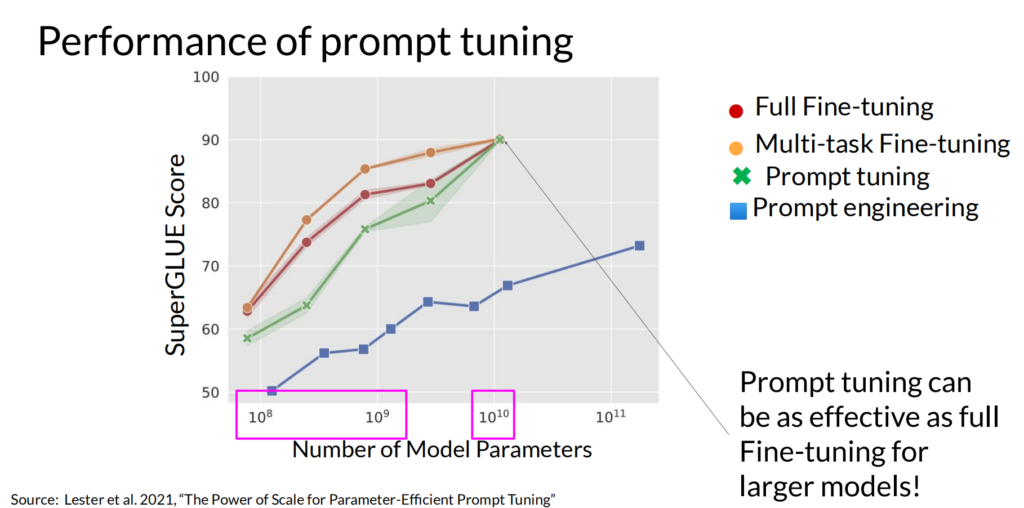
可以看到,当模型数量足够大时,几种方法的效果预期差距很小。
3.3 Reinforcement learning from human feedback (RLHF)
大模型的结果,经常会碰到输出的内容毫无意义,或者有攻击性、偏见等等情况,这时候就要再用人工标注的数据,进行一次强化学习。
首先要准备一批人工标注的数据,一般情况下,这样的数据量可能不够,不适合直接用于训练大模型,那就要用这批数据训练一个奖励模型,然后再用这个奖励模型,来对大模型进行训练:
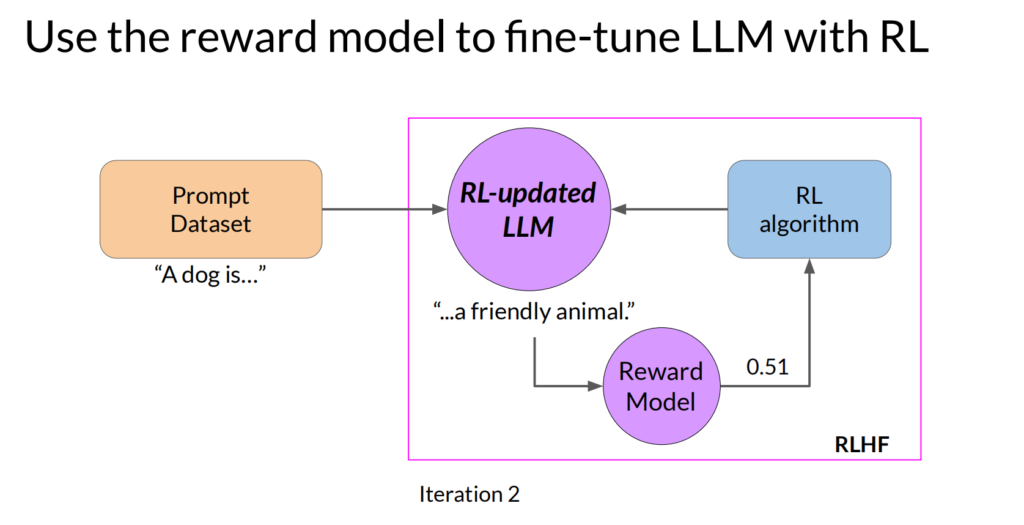
这里常用的强化学习算法就叫:Proximal Policy Optimization Algorithms (PPO),这里就不详细展开了。但是,我们会遇到一个问题,模型会过分关注奖励,导致结果不合理,这种情况叫reward hacking。要避免reward hacking,可以计算原始模型和强化学习以后模型输出的结果,把差异特别大的结果,进行额外惩罚。
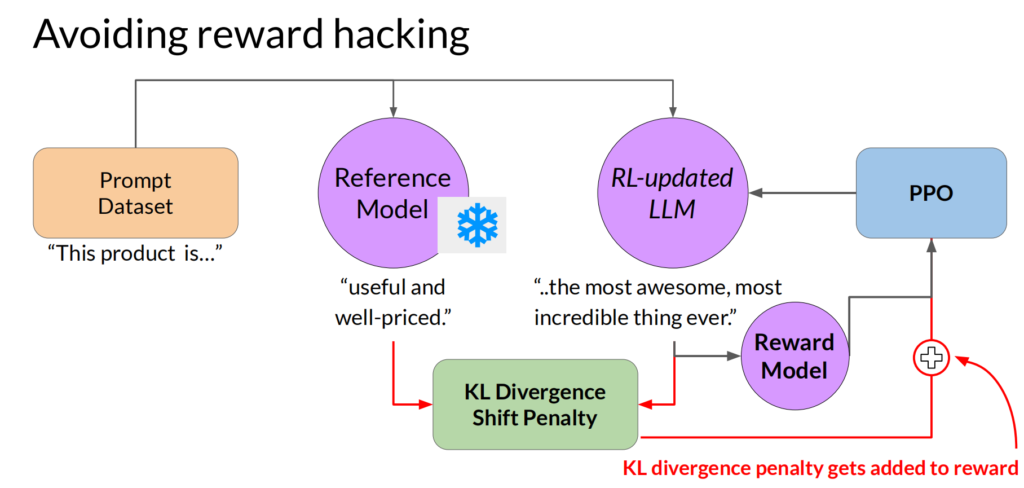
同样,我们可以用前面类似PEFT的方法,来替代直接更新所有模型参数,如下所示:
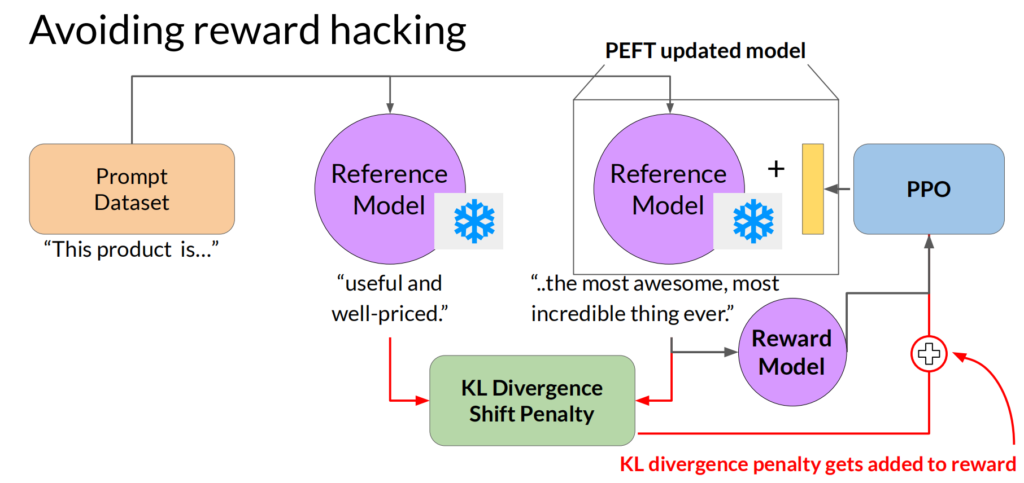
这里引出一个特别重要的概念,就是AI大模型的监管,如何让AI大模型是对人类有帮助而且无害的,可以参考:Constitutional AI: Harmlessness from AI Feedback
3.4 模型评价
针对应用场景,应该有自己的模型评价指标,课程里介绍了几种常用的,包括ROUGE、BLEU等,和常用的Benchmark:SuperGLUE、HELM
4. 模型部署:
4.1 模型压缩
符合要求的模型,在正式部署前,可以做模型压缩,一般有三条路线:
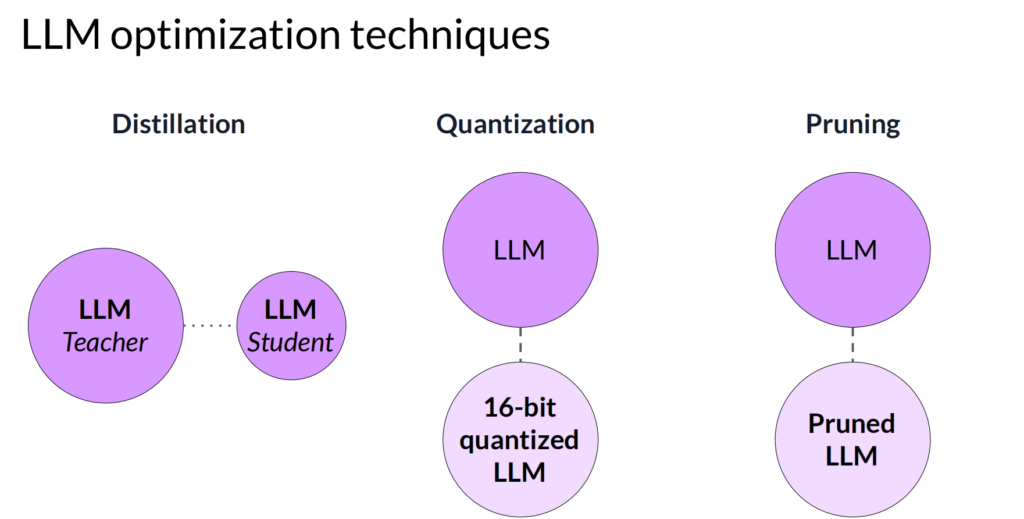
Distillation是用大模型来训练一个相对较小的模型
Quantization是降低大模型参数的精度,比如把16bit的浮点数降为8bit的整数
Pruning是去掉大模型中等于0或者非常接近0的参数
下面是几种对模型进行优化的方法对比:
4.2 模型与外部数据的连接
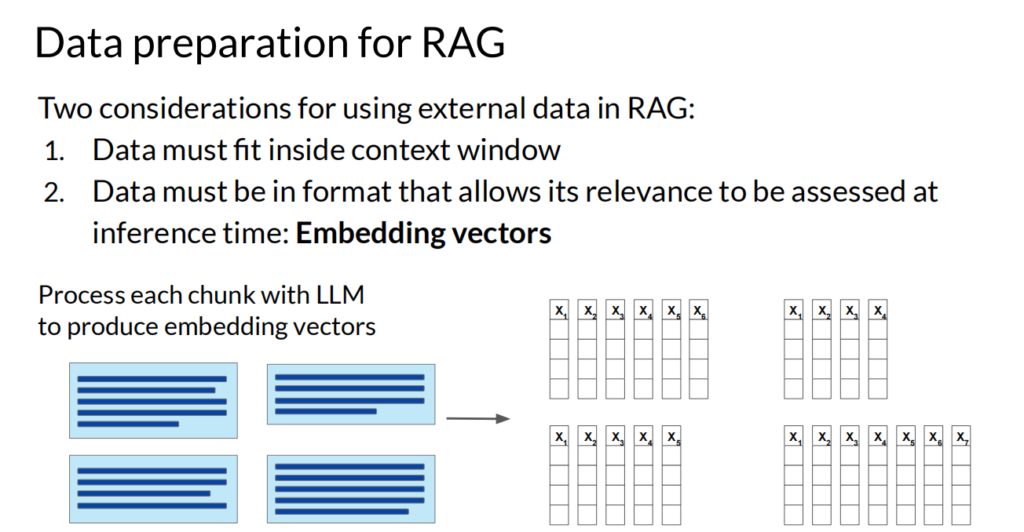
大模型一般基于公开数据、一定时间以前数据进行训练的,为了让大模型能够使用应用自身的数据、最新的数据,我们要用Retrieval augmented generation (RAG)技术和Agent技术。
RAG是通过检索外部数据、并向量化,然后传给大模型,来让大模型能够使用特定的数据
Agent就是通过调用API来使用其他应用的数据或者服务:
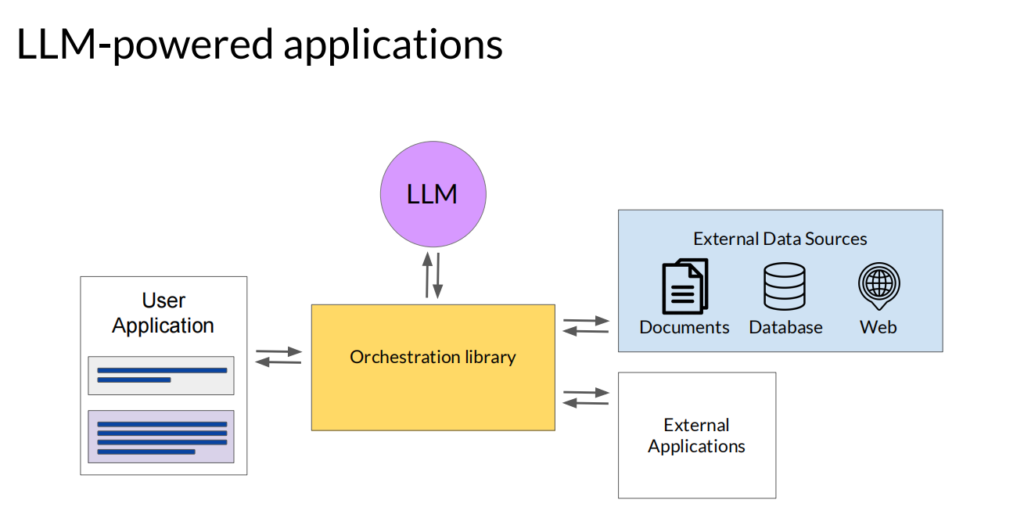
课程中举了Program-aided language (PAL) models和
4.3 基于大模型的应用架构
最后来看一下,一个基于大模型的应用的整体架构:
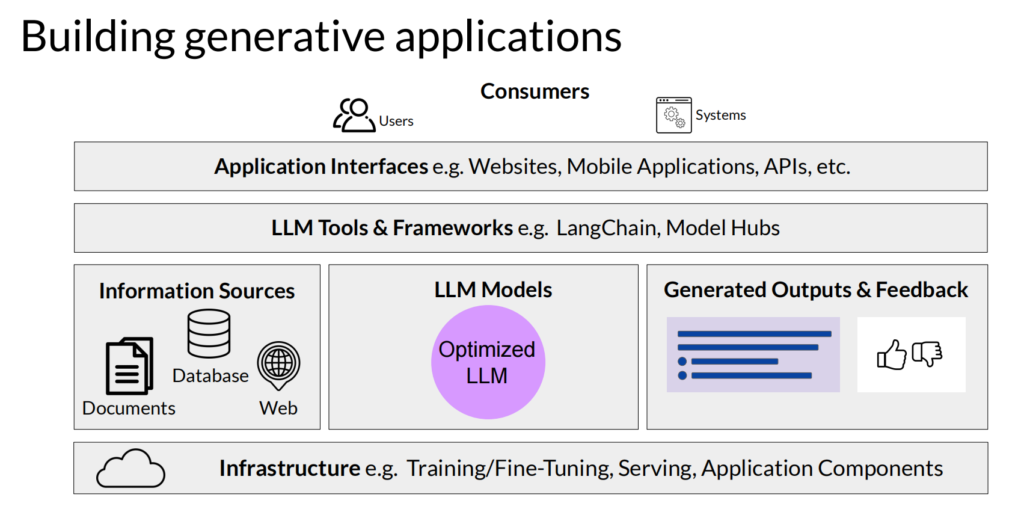
最底层是基础架构,包括训练和模型调优;上面一般是应用自己的特定数据源、模型本身和用户反馈数据;再上面是大模型工具集合,这个往往是开发工程量最大的部分;再上面就是应用自身的服务,比如网站、App、API等等。